扩展和启动步骤¶
自定义消息消费者¶
您可能希望嵌入自定义的 Kombu 消费者来手动处理消息。
为此,存在一个特殊的 celery.bootstep.ConsumerStep 启动步骤类,您只需要定义 get_consumers 方法,该方法必须返回一个 kombu.Consumer 对象列表,在连接建立时启动:
from celery import Celery
from celery import bootsteps
from kombu import Consumer, Exchange, Queue
my_queue = Queue('custom', Exchange('custom'), 'routing_key')
app = Celery(broker='amqp://')
class MyConsumerStep(bootsteps.ConsumerStep):
def get_consumers(self, channel):
return [Consumer(channel,
queues=[my_queue],
callbacks=[self.handle_message],
accept=['json'])]
def handle_message(self, body, message):
print('Received message: {0!r}'.format(body))
message.ack()
app.steps['consumer'].add(MyConsumerStep)
def send_me_a_message(who, producer=None):
with app.producer_or_acquire(producer) as producer:
producer.publish(
{'hello': who},
serializer='json',
exchange=my_queue.exchange,
routing_key='routing_key',
declare=[my_queue],
retry=True,
)
if __name__ == '__main__':
send_me_a_message('world!')
Note
Kombu 消费者可以使用两种不同的消息回调分发机制。第一种是 callbacks 参数,它接受具有 (body, message) 签名的回调列表;第二种是 on_message 参数,它接受具有 (message,) 签名的单个回调。后者不会自动解码和反序列化有效载荷。
def get_consumers(self, channel):
return [Consumer(channel, queues=[my_queue],
on_message=self.on_message)]
def on_message(self, message):
payload = message.decode()
print(
'Received message: {0!r} {props!r} rawlen={s}'.format(
payload, props=message.properties, s=len(message.body),
))
message.ack()
蓝图¶
Bootsteps 是一种为工作器添加功能的技术。一个 bootstep 是一个自定义类,它定义了在工作器的不同阶段执行自定义操作的钩子。每个 bootstep 都属于一个蓝图,工作器目前定义了两个蓝图:Worker 和 Consumer
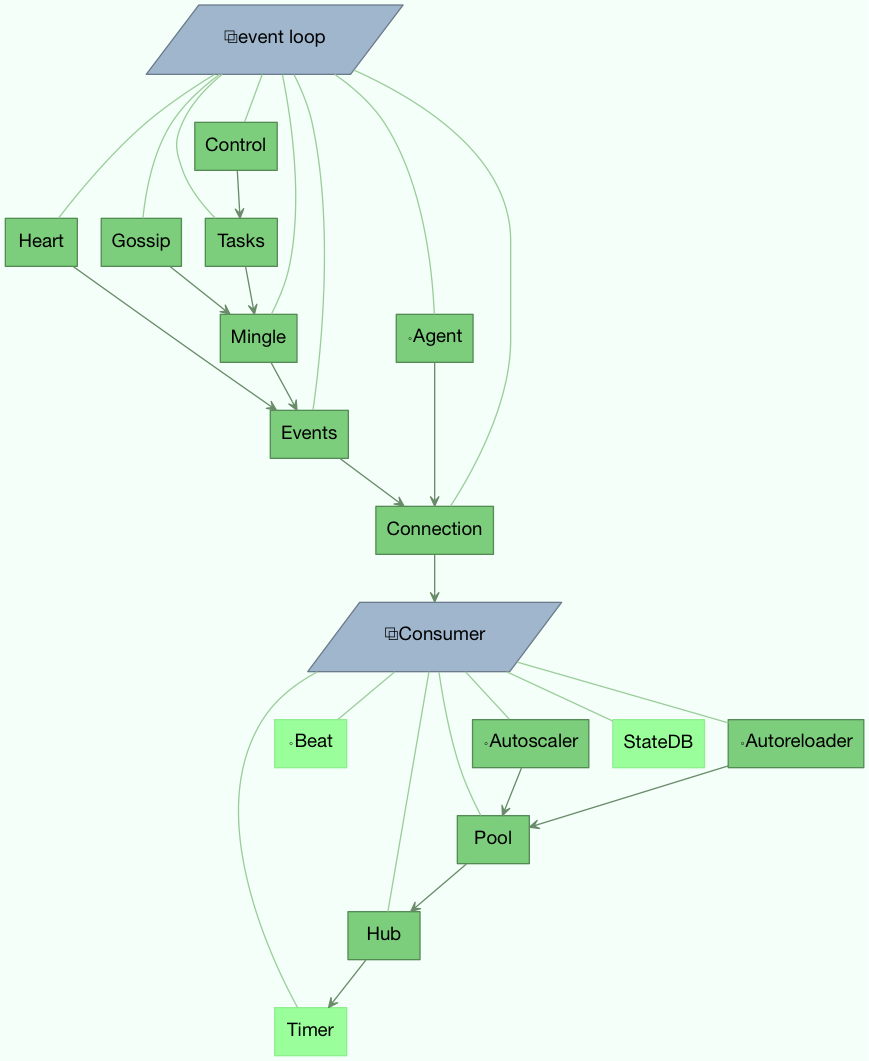
Worker¶
Worker 是第一个启动的蓝图,随之启动的还有主要组件,如事件循环、处理池以及用于 ETA 任务和其他定时事件的计时器。
当 worker 完全启动后,它会继续执行 Consumer 蓝图,该蓝图设置了任务的执行方式,连接到 broker 并启动消息消费者。
celery.worker.WorkController 是核心的 worker 实现,包含您可以在 bootstep 中使用的多个方法和属性。
属性¶
| 属性 | 描述 |
|---|---|
app |
当前的 app 实例。 |
hostname |
worker 的节点名称(例如:worker1@example.com) |
blueprint |
这是 worker 的 celery.bootsteps.Blueprint。 |
hub |
事件循环对象 (kombu.asynchronous.Hub)。您可以使用它在事件循环中注册回调函数。这仅受支持异步 I/O 的传输(amqp、redis)支持,在这种情况下,应设置 worker.use_eventloop 属性。您的 worker bootstep 必须要求 Hub bootstep 才能使用此功能: |
pool |
当前进程/eventlet/gevent/线程池。参见 celery.concurrency.base.BasePool。您的 worker bootstep 必须要求 Pool bootstep 才能使用此功能: |
timer |
kombu.asynchronous.timer.Timer 用于调度函数。您的 worker bootstep 必须要求 Timer bootstep 才能使用此功能: |
statedb |
celery.worker.state.Persistent 用于在 worker 重启之间
持久化状态。这仅在启用 statedb 参数时定义。您的 worker bootstep 必须要求 Statedb bootstep 才能使用此功能:
|
autoscaler |
celery.worker.autoscaler.Autoscaler 用于自动增长
和缩减池中的进程数量。这仅在启用 autoscale 参数时定义。您的 worker bootstep 必须要求 Autoscaler bootstep 才能使用此功能:
|
autoreloader |
celery.worker.autoreloader.Autoreloader 用于在文件系统更改时自动重新加载使用代码。这仅在启用 autoreload 参数时定义。您的 worker bootstep 必须要求 Autoreloader bootstep 才能使用此功能:
|
示例¶
一个示例 Worker bootstep 可以是:
from celery import bootsteps
class ExampleWorkerStep(bootsteps.StartStopStep):
requires = {'celery.worker.components:Pool'}
def __init__(self, worker, **kwargs):
print('Called when the WorkController instance is constructed')
print('Arguments to WorkController: {0!r}'.format(kwargs))
def create(self, worker):
# this method can be used to delegate the action methods
# to another object that implements `start` and `stop`.
return self
def start(self, worker):
print('Called when the worker is started.')
def stop(self, worker):
print('Called when the worker shuts down.')
def terminate(self, worker):
print('Called when the worker terminates')
每个方法都接收当前的 WorkController 实例作为第一个参数。
另一个示例可以使用计时器定期唤醒:
from celery import bootsteps
class DeadlockDetection(bootsteps.StartStopStep):
requires = {'celery.worker.components:Timer'}
def __init__(self, worker, deadlock_timeout=3600):
self.timeout = deadlock_timeout
self.requests = []
self.tref = None
def start(self, worker):
# run every 30 seconds.
self.tref = worker.timer.call_repeatedly(
30.0, self.detect, (worker,), priority=10,
)
def stop(self, worker):
if self.tref:
self.tref.cancel()
self.tref = None
def detect(self, worker):
# update active requests
for req in worker.active_requests:
if req.time_start and time() - req.time_start > self.timeout:
raise SystemExit()
自定义任务处理日志¶
Celery worker 会在任务生命周期的各个事件中向 Python 日志子系统发出消息。这些消息可以通过覆盖在 celery/app/trace.py 中定义的 LOG_<TYPE> 格式字符串来自定义。
例如:
import celery.app.trace
celery.app.trace.LOG_SUCCESS = "This is a custom message"
各种格式字符串都提供了任务名称和 ID 用于 % 格式化,其中一些还接收额外的字段,如返回值或导致任务失败的异常。这些字段可以在自定义格式字符串中使用,如下所示:
import celery.app.trace
celery.app.trace.LOG_REJECTED = "%(name)r is cursed and I won't run it: %(exc)s"
消费者¶
Consumer 蓝图建立与代理(broker)的连接,并且每次连接丢失时都会重新启动。Consumer 启动步骤包括工作节点心跳、远程控制命令消费者,以及重要的任务消费者。
当您创建 consumer 启动步骤时,必须考虑到必须能够重新启动您的蓝图。为 consumer 启动步骤定义了一个额外的 'shutdown' 方法,该方法在工作节点关闭时被调用。
属性¶
| 属性 | 描述 |
|---|---|
app |
当前的应用实例。 |
controller |
创建此 consumer 的父级 WorkController 对象。
|
hostname |
工作节点的名称(例如,worker1@example.com)
|
blueprint |
这是工作节点的 celery.bootsteps.Blueprint。
|
hub |
事件循环对象 (kombu.asynchronous.Hub)。您可以使用它在事件循环中注册回调函数。这仅支持启用异步I/O的传输(amqp、redis),在这种情况下,应设置 worker.use_eventloop 属性。您的工作节点启动步骤必须要求 Hub 启动步骤才能使用此功能:
|
connection |
当前的代理连接 (kombu.Connection)。consumer启动步骤必须要求 Connection 启动步骤才能使用此功能:
|
event_dispatcher |
一个 events.Dispatcher 对象,可用于发送事件。consumer 启动步骤必须要求 Events 启动步骤才能使用此功能。
|
gossip |
工作节点之间的广播通信 (celery.worker.consumer.gossip.Gossip)。consumer 启动步骤必须要求 Gossip 启动步骤才能使用此功能。
|
pool |
当前的进程/eventlet/gevent/线程池。参见 celery.concurrency.base.BasePool。
|
timer |
用于调度函数的 celery.utils.timer2.Schedule。
|
heart |
负责发送工作节点事件心跳(celery.worker.heartbeat.Heart)。您的 consumer 启动步骤必须要求 Heart 启动步骤才能使用此功能:
|
task_consumer |
用于消费任务消息的 kombu.Consumer 对象。您的 consumer 启动步骤必须要求 Tasks 启动步骤才能使用此功能:
|
strategies |
每个注册的任务类型在此映射中都有一个条目,其中值用于执行此任务类型的传入消息(任务执行策略)。此映射由Tasks启动步骤在 consumer 启动时生成:
Tasks 启动步骤才能使用此功能:
|
task_buckets |
一个 collections.defaultdict,用于按类型查找任务的速率限制。此字典中的条目可以是None(无限制)或实现 consume(tokens) 和 expected_time(tokens) 的 ~kombu.utils.limits.TokenBucket 实例。TokenBucket实现了[令牌桶算法](https://en.wikipedia.org/wiki/Token_bucket),但任何算法 只要符合相同的接口并定义上述两个方法都可以使用。 |
qos |
kombu.common.QoS 对象可用于更改任务通道当前的 prefetch_count 值:
|
方法¶
| 方法 | 描述 |
|---|---|
reset_rate_limits() |
更新所有注册任务类型的 task_buckets 映射。 |
bucket_for_task(type, Bucket=TokenBucket) |
使用任务的 task.rate_limit 属性为任务创建速率限制桶。 |
add_task_queue(name, exchange=None, exchange_type=None, routing_key=None, **options) |
添加新的队列以从中消费。这将在连接重启时持久化。 |
cancel_task_queue(name) |
按名称停止从队列消费。这将在连接重启时持久化。 |
apply_eta_task(request) |
根据 request.eta 属性调度ETA任务执行。 (celery.worker.request.Request) |
安装启动步骤¶
app.steps['worker'] 和 app.steps['consumer'] 可以被修改来添加新的启动步骤:
>>> app = Celery()
>>> app.steps['worker'].add(MyWorkerStep) # < 添加类,不要实例化
>>> app.steps['consumer'].add(MyConsumerStep)
>>> app.steps['consumer'].update([StepA, StepB])
>>> app.steps['consumer']
{step:proj.StepB{()}, step:proj.MyConsumerStep{()}, step:proj.StepA{()}
这里的步骤顺序并不重要,因为顺序是由产生的依赖图(Step.requires)决定的。
为了说明如何安装启动步骤以及它们如何工作,这是一个示例步骤,打印一些无用的调试信息。它可以同时作为 worker 和 consumer 的启动步骤添加:
from celery import Celery
from celery import bootsteps
class InfoStep(bootsteps.Step):
def __init__(self, parent, **kwargs):
# 在这里我们可以准备 Worker/Consumer 对象
# 以任何我们想要的方式,设置属性默认值等等。
print('{0!r} is in init'.format(parent))
def start(self, parent):
# 我们的步骤与所有其他 Worker/Consumer
# 启动步骤一起启动。
print('{0!r} is starting'.format(parent))
def stop(self, parent):
# Consumer 每次重启时(即连接丢失)以及关闭时都会调用 stop。
# Worker 仅在关闭时调用 stop。
print('{0!r} is stopping'.format(parent))
def shutdown(self, parent):
# shutdown 由 Consumer 在关闭时调用,
# Worker 不会调用它。
print('{0!r} is shutting down'.format(parent))
app = Celery(broker='amqp://')
app.steps['worker'].add(InfoStep)
app.steps['consumer'].add(InfoStep)
安装此步骤后启动 worker 将给我们以下日志:
<Worker: w@example.com (initializing)> is in init
<Consumer: w@example.com (initializing)> is in init
[2013-05-29 16:18:20,544: WARNING/MainProcess]
<Worker: w@example.com (running)> is starting
[2013-05-29 16:18:21,577: WARNING/MainProcess]
<Consumer: w@example.com (running)> is starting
<Consumer: w@example.com (closing)> is stopping
<Worker: w@example.com (closing)> is stopping
<Consumer: w@example.com (terminating)> is shutting down
print 语句将在 worker 初始化后重定向到日志子系统,因此 "is starting" 行带有时间戳。您可能会注意到在关闭时不再发生这种情况,这是因为 stop 和 shutdown 方法在 信号处理器 内部调用,在这样的处理器中使用日志记录是不安全的。
Python 日志记录模块不是 reentrant:意味着您不能中断函数然后稍后再次调用它。重要的是您编写的 stop 和 shutdown 方法也是 reentrant。
使用 celery worker --loglevel 启动 worker 将向我们显示有关启动过程的更多信息:
[2013-05-29 16:18:20,509: DEBUG/MainProcess] | Worker: Preparing bootsteps.
[2013-05-29 16:18:20,511: DEBUG/MainProcess] | Worker: Building graph...
<celery.apps.worker.Worker object at 0x101ad8410> is in init
[2013-05-29 16:18:20,511: DEBUG/MainProcess] | Worker: New boot order:
{Hub, Pool, Timer, StateDB, Autoscaler, InfoStep, Beat, Consumer}
[2013-05-29 16:18:20,514: DEBUG/MainProcess] | Consumer: Preparing bootsteps.
[2013-05-29 16:18:20,514: DEBUG/MainProcess] | Consumer: Building graph...
<celery.worker.consumer.Consumer object at 0x101c2d8d0> is in init
[2013-05-29 16:18:20,515: DEBUG/MainProcess] | Consumer: New boot order:
{Connection, Mingle, Events, Gossip, InfoStep, Agent,
Heart, Control, Tasks, event loop}
[2013-05-29 16:18:20,522: DEBUG/MainProcess] | Worker: Starting Hub
[2013-05-29 16:18:20,522: DEBUG/MainProcess] ^-- substep ok
[2013-05-29 16:18:20,522: DEBUG/MainProcess] | Worker: Starting Pool
[2013-05-29 16:18:20,542: DEBUG/MainProcess] ^-- substep ok
[2013-05-29 16:18:20,543: DEBUG/MainProcess] | Worker: Starting InfoStep
[2013-05-29 16:18:20,544: WARNING/MainProcess]
<celery.apps.worker.Worker object at 0x101ad8410> is starting
[2013-05-29 16:18:20,544: DEBUG/MainProcess] ^-- substep ok
[2013-05-29 16:18:20,544: DEBUG/MainProcess] | Worker: Starting Consumer
[2013-05-29 16:18:20,544: DEBUG/MainProcess] | Consumer: Starting Connection
[2013-05-29 16:18:20,559: INFO/MainProcess] Connected to amqp://guest@127.0.0.1:5672//
[2013-05-29 16:18:20,560: DEBUG/MainProcess] ^-- substep ok
[2013-05-29 16:18:20,560: DEBUG/MainProcess] | Consumer: Starting Mingle
[2013-05-29 16:18:20,560: INFO/MainProcess] mingle: searching for neighbors
[2013-05-29 16:18:21,570: INFO/MainProcess] mingle: no one here
[2013-05-29 16:18:21,570: DEBUG/MainProcess] ^-- substep ok
[2013-05-29 16:18:21,571: DEBUG/MainProcess] | Consumer: Starting Events
[2013-05-29 16:18:21,572: DEBUG/MainProcess] ^-- substep ok
[2013-05-29 16:18:21,572: DEBUG/MainProcess] | Consumer: Starting Gossip
[2013-05-29 16:18:21,577: DEBUG/MainProcess] ^-- substep ok
[2013-05-29 16:18:21,577: DEBUG/MainProcess] | Consumer: Starting InfoStep
[2013-05-29 16:18:21,577: WARNING/MainProcess]
<celery.worker.consumer.Consumer object at 0x101c2d8d0> is starting
[2013-05-29 16:18:21,578: DEBUG/MainProcess] ^-- substep ok
[2013-05-29 16:18:21,578: DEBUG/MainProcess] | Consumer: Starting Heart
[2013-05-29 16:18:21,579: DEBUG/MainProcess] ^-- substep ok
[2013-05-29 16:18:21,579: DEBUG/MainProcess] | Consumer: Starting Control
[2013-05-29 16:18:21,583: DEBUG/MainProcess] ^-- substep ok
[2013-05-29 16:18:21,583: DEBUG/MainProcess] | Consumer: Starting Tasks
[2013-05-29 16:18:21,606: DEBUG/MainProcess] basic.qos: prefetch_count->80
[2013-05-29 16:18:21,606: DEBUG/MainProcess] ^-- substep ok
[2013-05-29 16:18:21,606: DEBUG/MainProcess] | Consumer: Starting event loop
[2013-05-29 16:18:21,608: WARNING/MainProcess] celery@example.com ready.
命令行程序¶
添加新的命令行选项¶
命令特定选项¶
您可以通过修改应用程序实例的 user_options 属性来向 worker、beat 和 events 命令添加额外的命令行选项。
Celery 命令使用 click 模块来解析命令行参数,因此要添加自定义参数,您需要向相关集合添加 click.Option 实例。
向 celery worker 命令添加自定义选项的示例:
from celery import Celery
from click import Option
app = Celery(broker='amqp://')
app.user_options['worker'].add(Option(('--enable-my-option',),
is_flag=True,
help='Enable custom option.'))
所有引导步骤现在都将此参数作为关键字参数传递给 Bootstep.__init__:
from celery import bootsteps
class MyBootstep(bootsteps.Step):
def __init__(self, parent, enable_my_option=False, **options):
super().__init__(parent, **options)
if enable_my_option:
party()
app.steps['worker'].add(MyBootstep)
预加载选项¶
celery 伞形命令支持'预加载选项'的概念。这些是传递给所有子命令的特殊选项。
您可以添加新的预加载选项,例如指定配置模板:
from celery import Celery
from celery import signals
from click import Option
app = Celery()
app.user_options['preload'].add(Option(('-Z', '--template'),
default='default',
help='Configuration template to use.'))
@signals.user_preload_options.connect
def on_preload_parsed(options, **kwargs):
use_template(options['template'])
添加新的 celery 子命令¶
可以通过使用 setuptools 入口点 向 celery 伞形命令添加新命令。
入口点是特殊的元数据,可以添加到包的 setup.py 程序中,然后在安装后使用 importlib 模块从系统中读取。
Celery 识别 celery.commands 入口点来安装额外的子命令,其中入口点的值必须指向有效的 click 命令。
这就是 Flower 监控扩展如何通过向 setup.py 添加入口点来添加 celery flower 命令的方式:
setup(
name='flower',
entry_points={
'celery.commands': [
'flower = flower.command:flower',
],
}
)
命令定义由等号分隔为两部分,第一部分是子命令的名称(flower),第二部分是实现命令的函数的完全限定符号路径:
flower.command:flower
模块路径和属性名称应如上所示用冒号分隔。
在 flower/command.py 模块中,命令函数可以定义如下:
import click
@click.command()
@click.option('--port', default=8888, type=int, help='Webserver port')
@click.option('--debug', is_flag=True)
def flower(port, debug):
print('Running our command')
Worker API¶
kombu.asynchronous.Hub - 工作者的异步事件循环
当使用amqp或redis代理传输时,工作者使用异步I/O。最终目标是所有传输都使用事件循环,但这需要一些时间,因此其他传输仍然使用基于线程的解决方案。
| Method | Description |
|---|---|
add(fd, callback, flags) |
- |
add_reader(fd, callback, *args) |
添加回调函数,当 fd 可读时调用。回调将保持注册状态,直到显式移除使用 hub.remove(fd),或者文件描述符因不再有效而自动丢弃。注意,在任何给定的文件描述符上,一次只能注册一个回调函数,因此第二次调用 add 将移除之前为该文件描述符注册的任何回调函数。文件描述符可以是任何支持 fileno 方法的类文件对象,也可以是文件描述符编号(int)。 |
add_writer(fd, callback, *args) |
添加回调函数,当 fd 可写时调用。另请参见上面的 hub.add_reader 注释。 |
remove(fd) |
从循环中移除文件描述符 fd 的所有回调函数。 |
Timer - 调度事件¶
| Method |
|---|
call_after(secs, callback, args=(), kwargs=(), priority=0) |
call_repeatedly(secs, callback, args=(), kwargs=(), priority=0) |
call_at(eta, callback, args=(), kwargs=(), priority=0) |